Vocal Call Locator Benchmark (VCL) for Localizing Rodent Vocalizations From Multichannel Audio
Ralph E Peterson1,2*, Aramis Tanelus2*, Christopher Ick3, Bartul Mimica4, Niegil Francis1,5, Violet J Ivan1, Aman Choudhri6, Annegret L Falkner4, Mala Murthy4, David M Schneider1, Dan H Sanes1, Alex H Williams1,2†
1NYU, Center for Neural Science
2Flatiron Institute, Center for
Computational Neuroscience
3NYU, Center for Data Science
4Princeton Neuroscience Institute
5NYU, Tandon School of Engineering
6Columbia University
Abstract
Understanding the behavioral and neural dynamics of social interactions is a goal of contemporary neuroscience. Many machine learning methods have emerged in recent years to make sense of complex video and neurophysiological data that result from these experiments. Less focus has been placed on understanding how animals process acoustic information, including social vocalizations. A critical step to bridge this gap is determining the senders and receivers of acoustic information in social interactions. While sound source localization (SSL) is a classic problem in signal processing, existing approaches are limited in their ability to localize animal-generated sounds in standard laboratory environments. Advances in deep learning methods for SSL are likely to help address these limitations, however there are currently no publicly available models, datasets, or benchmarks to systematically evaluate SSL algorithms in the domain of bioacoustics. Here, we present the VCL Benchmark: the first large-scale dataset for benchmarking SSL algorithms in rodents. We acquired synchronized video and multi-channel audio recordings of 767,295 sounds with annotated ground truth sources across 9 conditions. The dataset provides benchmarks which evaluate SSL performance on real data, simulated acoustic data, and a mixture of real and simulated data. We intend for this benchmark to facilitate knowledge transfer between the neuroscience and acoustic machine learning communities, which have had limited overlap.



*Equal contribution
†Correspondence to
rep359@nyu.edu and alex.h.williams@nyu.edu
Datasets

A dataset of sounds emitted by a stationary speaker at ~400 positions.
Size: 15GB

A dataset of sounds emitted by an Edison robot performing a random walk around Environment 1.
Size: 44GB

A dataset of vocalizations emitted by lone, freely-behaving adolescent gerbils in response to vocalizations presented through a speaker.
Size: 7.5GB

A dataset of spontaneous vocalizations emitted by various pairings of two gerbils.
Size: 86MB

A dataset of sounds emitted by an earbud affixed to the head of a freely-behaving adult gerbil.
Size: 1.3GB

A dataset of sounds emitted by an ultrasonic speaker affixed to a hexapod robot walking in parallel lines across Environment 2.
Size: 236GB

A dataset of sounds emitted by an earbud affixed to the head of a lone, freely-behaving mouse.
Size: 208GB
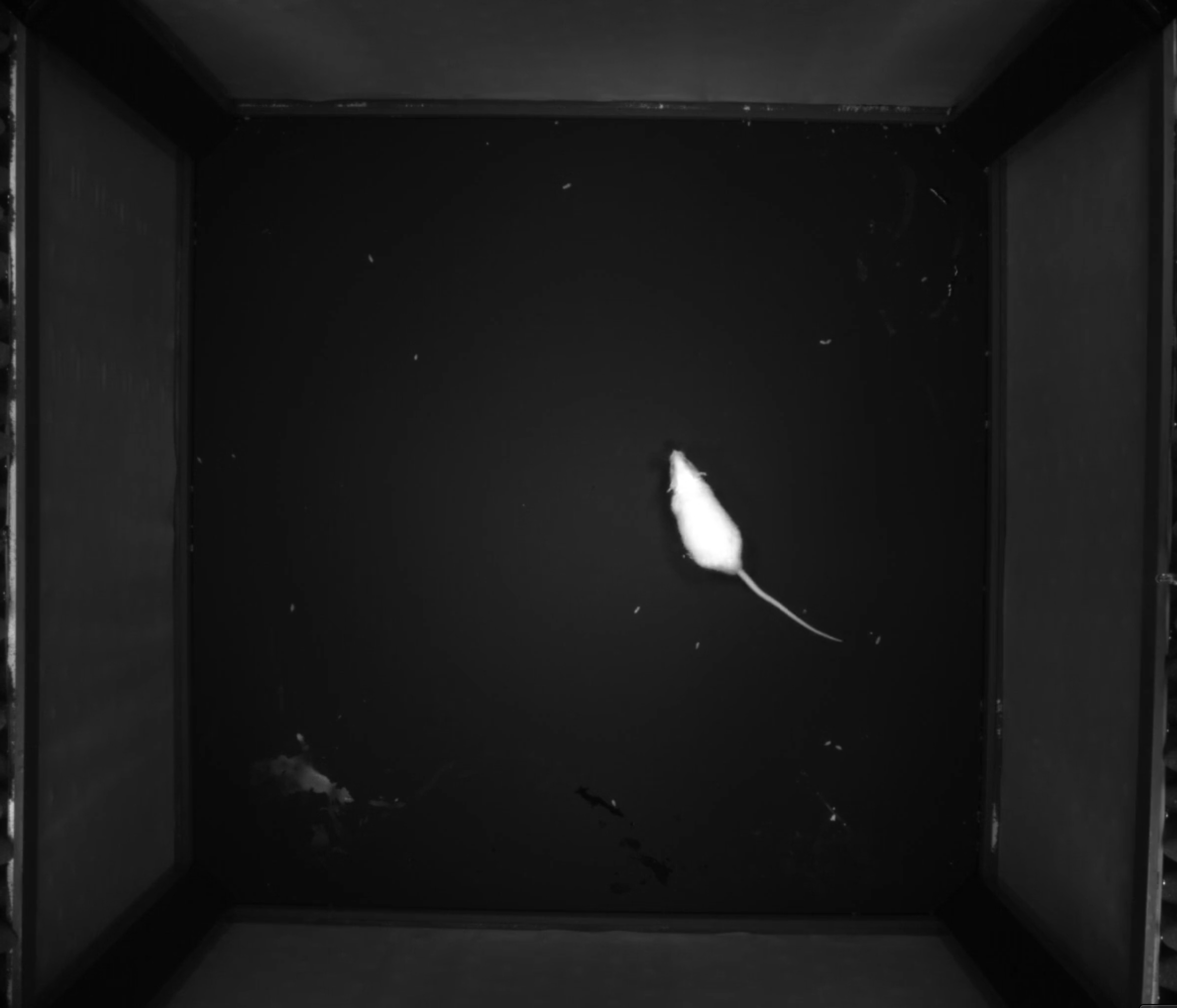
A dataset of vocalizations emitted by a freely-behaving mouse.
Size: 362MB

A dataset of vocalizations emitted by two freely-behaving mice.
Size: 2.1GB
Environments
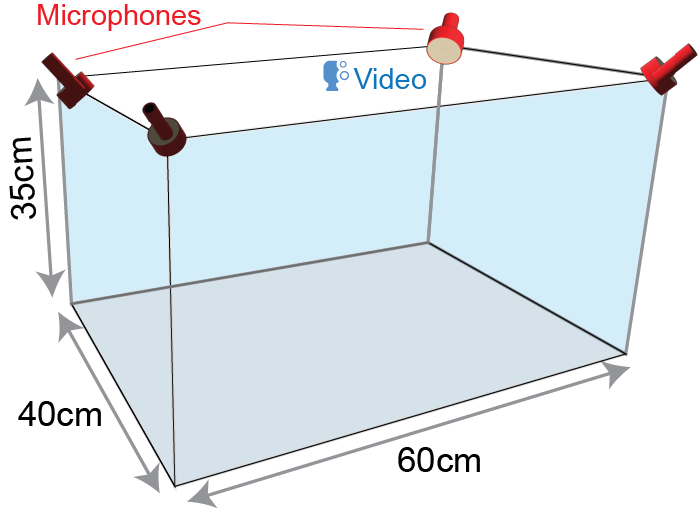
A prismic environment with hard plastic walls, acoustic foam lining the ceiling, and an inch of bedding on the floor.
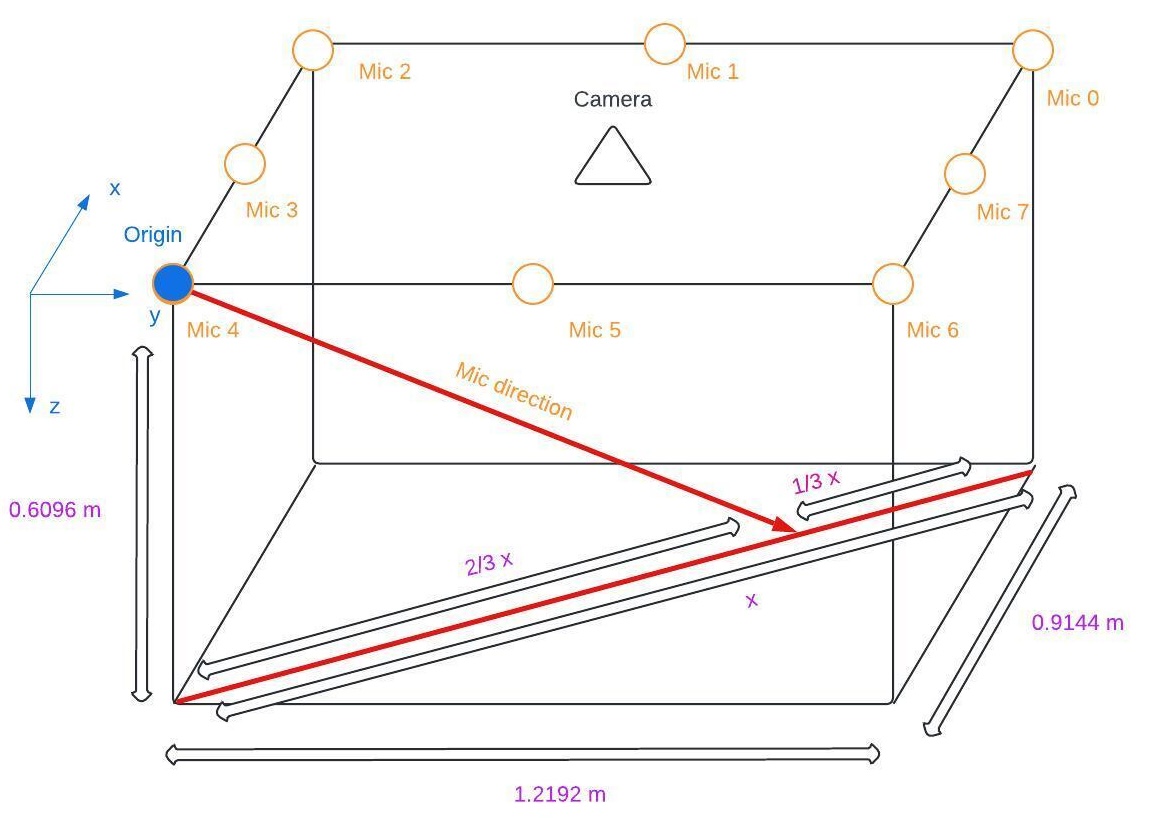
A prismic environment with hard plastic for its walls and ceiling and a layer of bedding on its floor.

A square environment with acoustically transparent walls and a Lexane floor.